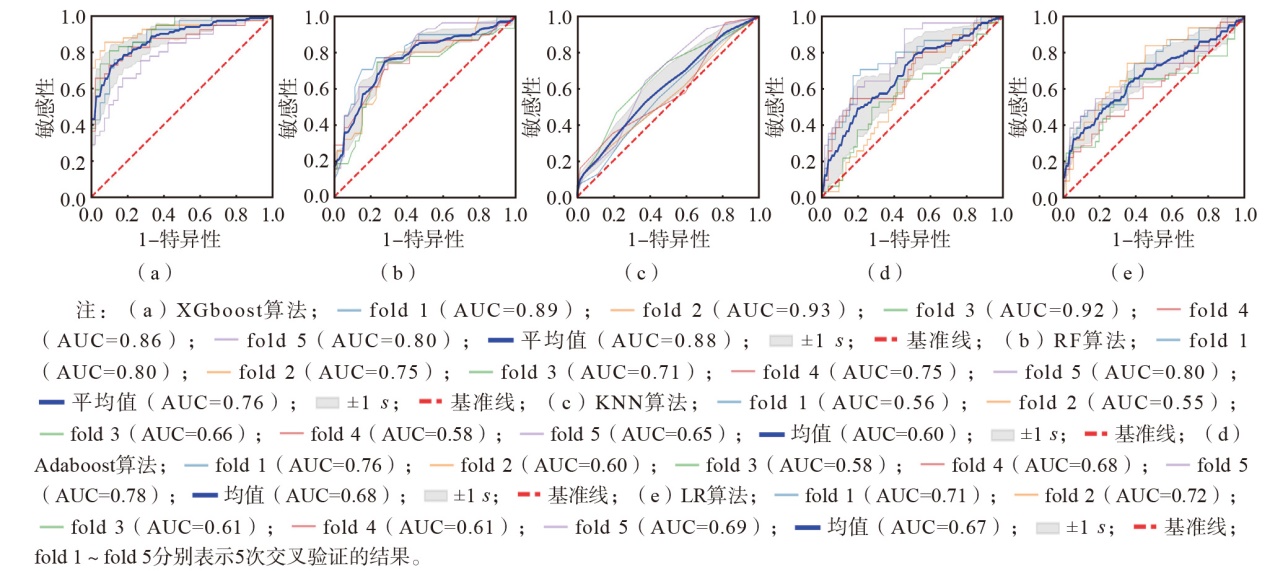
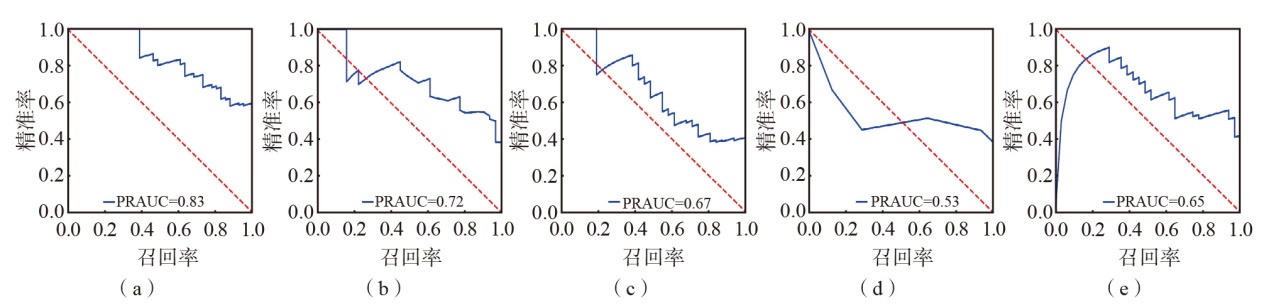
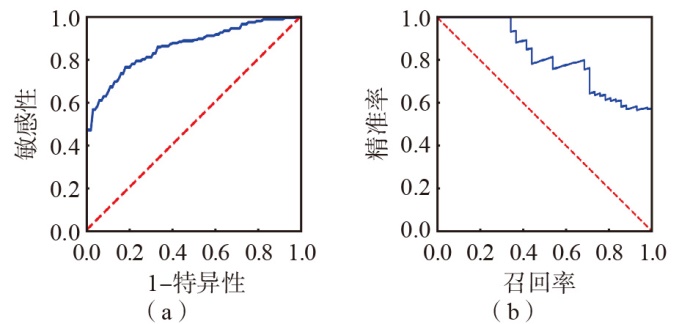
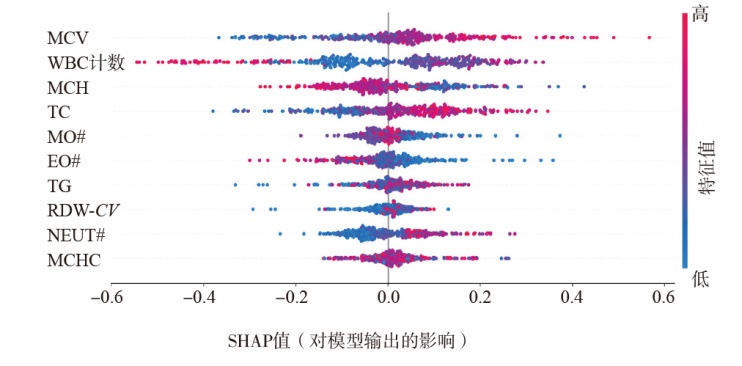
| [1] |
GBD 2019 Stroke Collaborators. Global,regional,and national burden of stroke and its risk factors,1990-2019:a systematic analysis for the Global Burden of Disease Study 2019[J]. Lancet Neurol,2021, 20(10):795-820.
|
| [2] |
DONKOR E S. Stroke in the 21st century:a snapshot of the burden,epidemiology,and quality of life[J]. Stroke Res Treat, 2018,2018:3238165.
|
| [3] |
DING Q, LIU S, YAO Y, et al. Global,regional,and national burden of ischemic stroke,1990-2019[J]. Neurology, 2022, 98(3):e279-e290.
|
| [4] |
VODENCAREVIC A, WEINGÄRTNER M, CARO J J, et al. Prediction of recurrent ischemic stroke using registry data and machine learning methods:the erlangen stroke registry[J]. Stroke, 2022, 53(7):2299-2306.
|
| [5] |
SUMI S, ORIGASA H, HOUKIN K, et al. A modified Essen stroke risk score for predicting recurrent cardiovascular events:development and validation[J]. Int J Stroke, 2013, 8(4):251-257.
|
| [6] |
DIENER H C, RINGLEB P A, SAVI P. Clopidogrel for the secondary prevention of stroke[J]. Expert Opin Pharmacother, 2005, 6(5):755-764.
|
| [7] |
FENG G H, LI H P, LI Q L, et al. Red blood cell distribution width and ischaemic stroke[J]. Stroke Vasc Neurol, 2017, 2(3):172-175.
|
| [8] |
LAPPEGÅRD J, ELLINGSEN T S, SKJELBAKKEN T, et al. Red cell distribution width is associated with future risk of incident stroke[J]. Thromb Haemost, 2016, 115(1):126-134.
|
| [9] |
刘淑静, 常欣魁, 陈柯霖, 等. 载脂蛋白E基因多态性与脑梗患者年龄和血脂的相关性研究[J]. 标记免疫分析与临床, 2018, 25(11):1595-1598.
|
| [10] |
BUSHNELL C, KERNAN W N, SHARRIEF A Z, et al. 2024 guideline for the primary prevention of stroke:a guideline from the American Heart Association/American Stroke Association[J]. Stroke, 2024, 55(12):e344-e424.
|
| [11] |
PERERA K S, DE SA BOASQUEVISQUE D, RAO-MELACINI P, et al. Evaluating rates of recurrent ischemic stroke among young adults with embolic stroke of undetermined source:the young ESUS longitudinal cohort study[J]. JAMA Neurol, 2022, 79(5):450-458.
|
| [12] |
王双, 陈思, 付阳, 等. 机器学习在血细胞分析中智能筛查原始细胞的应用[J]. 检验医学, 2019, 34(12):1118-1123.
DOI
|
| [13] |
贾音, 孙婷婷, 刘海东, 等. 常规检验大数据在胃癌早期诊断中的应用[J]. 中华检验医学杂志, 2021, 44(3):197-203.
|
| [14] |
郭杰, 刘海东, 韦琴, 等. 基于检验大数据的结直肠癌风险预测模型建立与验证[J]. 中华检验医学杂志, 2021, 44(10):914-920.
|
| [15] |
HE M, WANG H, TANG Y, et al. Red blood cell distribution width in different time-points of peripheral thrombolysis period in acute ischemic stroke is associated with prognosis[J]. Aging(Albany NY), 2022, 14(14):5749-5767.
|
| [16] |
SHEN Z, HUANG Y, ZHOU Y, et al. Association between red blood cell distribution width and ischemic stroke recurrence in patients with acute ischemic stroke:a 10-years retrospective cohort analysis[J]. Aging(Albany NY), 2023, 15(8):3052-3063.
|
| [17] |
JIA Y P, WANG J M, LYU J Q, et al. Triglyceride-rich lipoproteins cholesterol,10-years atherosclerotic cardiovascular disease risk,and risk of myocardial infarction and ischemic stroke[J]. J Lipid Res, 2024, 65(11):100653.
|
| [18] |
彭蘡, 黄婷, 徐燕. 载脂蛋白E、三酰甘油、LDL-C及联合检测在早期动脉粥样硬化性脑梗死患者中的应用价值[J]. 医学信息, 2023, 36(20):99-102.
|


 )
)