
Laboratory Medicine ›› 2025, Vol. 40 ›› Issue (11): 1075-1081.DOI: 10.3969/j.issn.1673-8640.2025.11.008
Previous Articles Next Articles
QI Xinglun, YAO Yifan, SHEN Shushi, YANG Zheng, ZHU Junjie, FAN Lina, YANG Dagan( )
)
Received:2025-06-04
Revised:2025-09-22
Online:2025-11-30
Published:2025-12-12
CLC Number:
QI Xinglun, YAO Yifan, SHEN Shushi, YANG Zheng, ZHU Junjie, FAN Lina, YANG Dagan. Performance evaluation of different large language models in interpreting tumor marker determination reports[J]. Laboratory Medicine, 2025, 40(11): 1075-1081.
Add to citation manager EndNote|Ris|BibTeX
URL: https://www.shjyyx.com/EN/10.3969/j.issn.1673-8640.2025.11.008
| 质量维度 | 1~2分 | 3~4分 | 5~7分 | 8~9分 | 10分 |
|---|---|---|---|---|---|
| 全面性 | 遗漏绝大多数关键信息 | 包含少量关键信息,遗漏多个重要方面 | 包含多数关键信息,但遗漏少量重要内容 | 包含几乎所有关键信 息,在次要方面略简 | 完整涵盖所有关键信息 |
| 准确性 | 存在严重医学事实错误或误导性陈述 | 有数个明显医学错误或表述不严谨 | 主体信息准确,有不精确表述 | 信息高度准确,个别细节可更精确 | 所有信息描述完全准确无误 |
| 清晰度 | 语言晦涩难懂,逻辑混乱,专业术语无解释 | 表述较为混乱或冗长,部分关键点表述不清 | 整体可读,但部分内容不够简洁明或结构松散 | 语言流畅,逻辑清晰,结构合理,关键信息易获取 | 表达极精炼、通俗、逻辑严谨,结构清晰 |
| 相关性 | 包含大量无关信息、过度推测 | 包含部分无关内容或建议略显宽泛/不相关 | 主要内容相关,但偶有稍显冗余或不相关内容 | 内容聚焦报告结果,建议具体且有针对性 | 内容基于报告信息,建议精准、务实、有用 |
| 质量维度 | 1~2分 | 3~4分 | 5~7分 | 8~9分 | 10分 |
|---|---|---|---|---|---|
| 全面性 | 遗漏绝大多数关键信息 | 包含少量关键信息,遗漏多个重要方面 | 包含多数关键信息,但遗漏少量重要内容 | 包含几乎所有关键信 息,在次要方面略简 | 完整涵盖所有关键信息 |
| 准确性 | 存在严重医学事实错误或误导性陈述 | 有数个明显医学错误或表述不严谨 | 主体信息准确,有不精确表述 | 信息高度准确,个别细节可更精确 | 所有信息描述完全准确无误 |
| 清晰度 | 语言晦涩难懂,逻辑混乱,专业术语无解释 | 表述较为混乱或冗长,部分关键点表述不清 | 整体可读,但部分内容不够简洁明或结构松散 | 语言流畅,逻辑清晰,结构合理,关键信息易获取 | 表达极精炼、通俗、逻辑严谨,结构清晰 |
| 相关性 | 包含大量无关信息、过度推测 | 包含部分无关内容或建议略显宽泛/不相关 | 主要内容相关,但偶有稍显冗余或不相关内容 | 内容聚焦报告结果,建议具体且有针对性 | 内容基于报告信息,建议精准、务实、有用 |
| 类别 | 例数 | 性别 | 0~14岁 患儿/岁 | 15~64岁 患者/岁 | ≥65岁 患者/岁 | 正常/例 | 异常/例 | 检验项目/个 | |
|---|---|---|---|---|---|---|---|---|---|
| 男/例 | 女/例 | ||||||||
| 常见病 | 120 | 60 | 60 | 11±3 | 52±10 | 73±6 | 36 | 84 | 6.0±0.9① |
| 罕见病 | 40 | 20 | 20 | 7±2 | 49±10 | 71±5 | 14 | 26 | 6.0±0.2 |
| 危重症 | 40 | 20 | 2 | 6±6 | 43±16 | 75±8 | 14 | 26 | 6.0±0.7 |
| 类别 | 例数 | 性别 | 0~14岁 患儿/岁 | 15~64岁 患者/岁 | ≥65岁 患者/岁 | 正常/例 | 异常/例 | 检验项目/个 | |
|---|---|---|---|---|---|---|---|---|---|
| 男/例 | 女/例 | ||||||||
| 常见病 | 120 | 60 | 60 | 11±3 | 52±10 | 73±6 | 36 | 84 | 6.0±0.9① |
| 罕见病 | 40 | 20 | 20 | 7±2 | 49±10 | 71±5 | 14 | 26 | 6.0±0.2 |
| 危重症 | 40 | 20 | 2 | 6±6 | 43±16 | 75±8 | 14 | 26 | 6.0±0.7 |
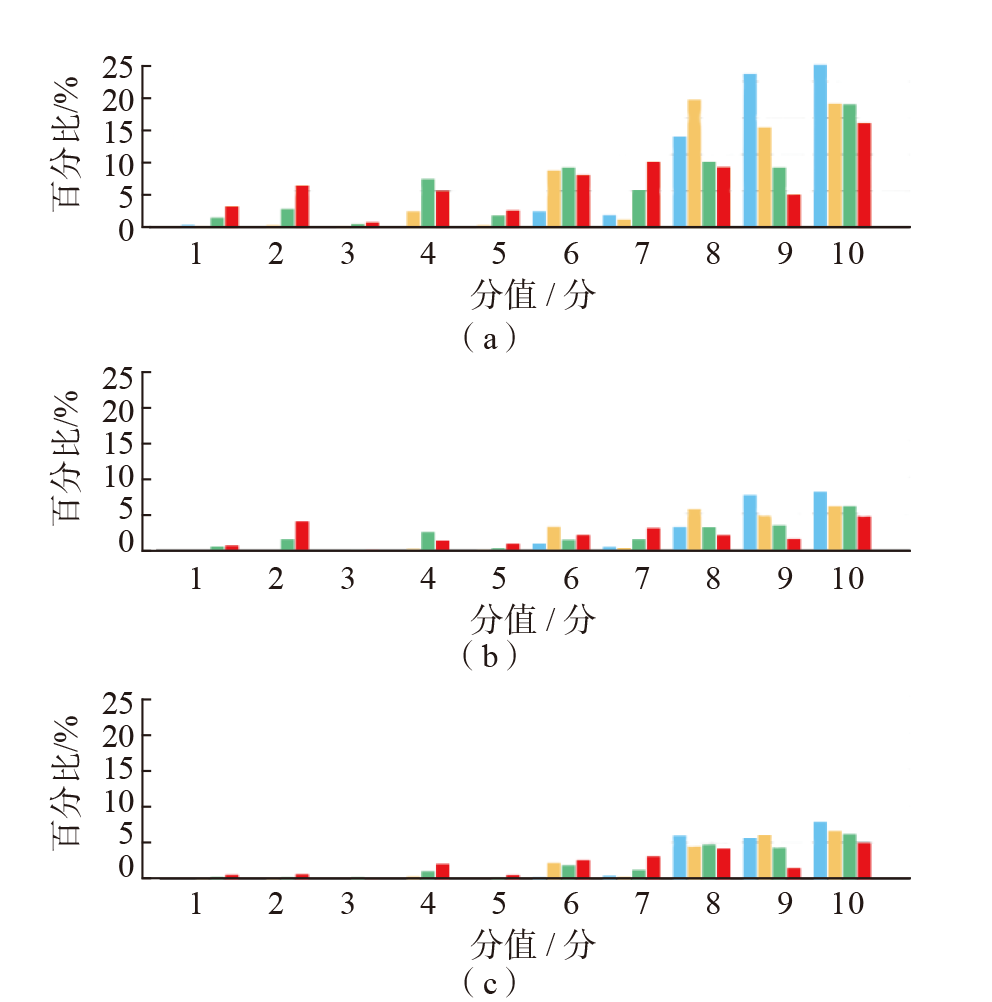
| 大语言模型 | 评分/分 | ρ值 | α值 | 组内相关系数 | P值 |
|---|---|---|---|---|---|
| DeepSeek R1 | |||||
| 初级评估者 | 9(9,10) | 0.656 | 0.711 | 0.684 | 0.414 |
| 资深评估者 | 9(8,10) | 0.631 | 0.660 | 0.625 | |
| Qwen 3 | |||||
| 初级评估者 | 9(8,10) | 0.628 | 0.723 | 0.722 | <0.001 |
| 资深评估者 | 8(6,10) | 0.763 | 0.754 | 0.657 | |
| KIMI | |||||
| 初级评估者 | 9(7,10) | 0.725 | 0.767 | 0.686 | <0.001 |
| 资深评估者 | 8(4,10) | 0.828 | 0.851 | 0.801 | |
| ChatGPT 4.1 | |||||
| 初级评估者 | 7(6,9) | 0.584 | 0.710 | 0.699 | <0.001 |
| 资深评估者 | 7(4,10) | 0.726 | 0.775 | 0.727 |
| 大语言模型 | 评分/分 | ρ值 | α值 | 组内相关系数 | P值 |
|---|---|---|---|---|---|
| DeepSeek R1 | |||||
| 初级评估者 | 9(9,10) | 0.656 | 0.711 | 0.684 | 0.414 |
| 资深评估者 | 9(8,10) | 0.631 | 0.660 | 0.625 | |
| Qwen 3 | |||||
| 初级评估者 | 9(8,10) | 0.628 | 0.723 | 0.722 | <0.001 |
| 资深评估者 | 8(6,10) | 0.763 | 0.754 | 0.657 | |
| KIMI | |||||
| 初级评估者 | 9(7,10) | 0.725 | 0.767 | 0.686 | <0.001 |
| 资深评估者 | 8(4,10) | 0.828 | 0.851 | 0.801 | |
| ChatGPT 4.1 | |||||
| 初级评估者 | 7(6,9) | 0.584 | 0.710 | 0.699 | <0.001 |
| 资深评估者 | 7(4,10) | 0.726 | 0.775 | 0.727 |
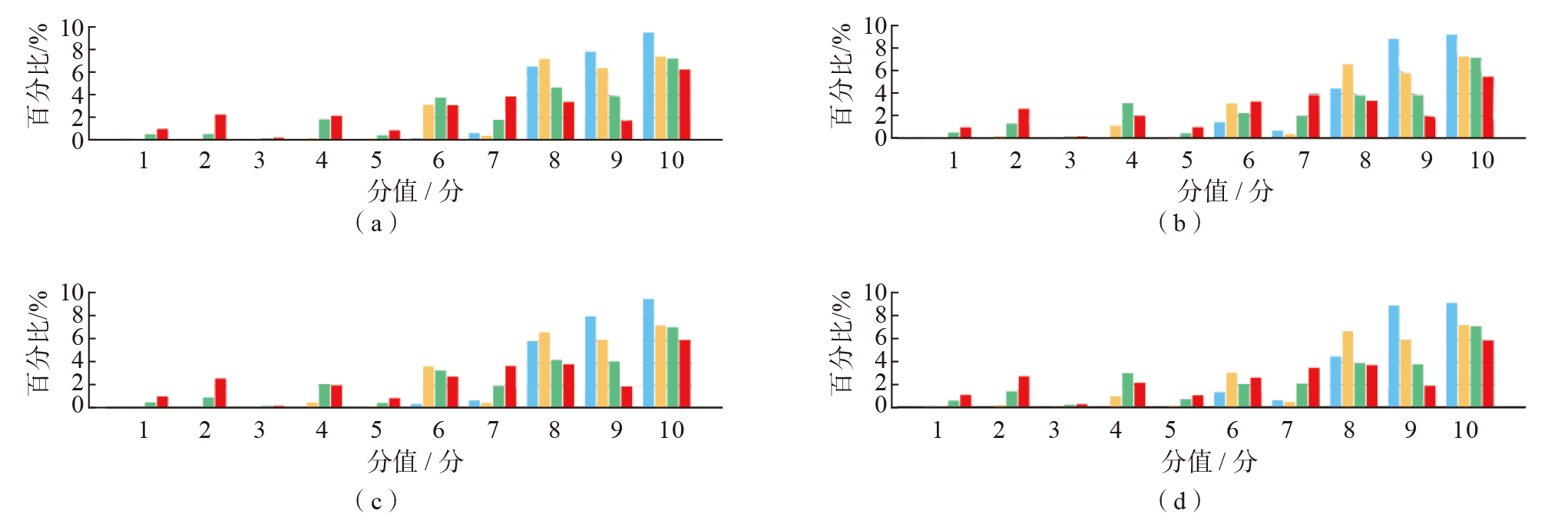
| LLM | 异常指标识别/分 | 异常原因分析/分 | 临床建议/分 | “幻觉”病例数/分 |
|---|---|---|---|---|
| DeepSeek R1 | ||||
| 常见病 | 10(10,10) | 9(8,9) | 9(8,9) | 6 |
| 罕见病 | 10(10,10) | 9(9,9) | 9(8,9) | 0 |
| 危重症 | 10(10,10) | 9(8,9) | 8(8,9) | 0 |
| 合计 | 10(10,10) | 9(8,9) | 8(8,9) | 6 |
| Qwen 3 | ||||
| 常见病 | 10(10,10) | 8(6,8) | 8(7,9) | 5 |
| 罕见病 | 10(10,10) | 8(6,8) | 8(7,9) | 0 |
| 危重症 | 10(10,10) | 8(6,9) | 9(8,9) | 0 |
| 合计 | 10(10,10) | 8(6,8) | 8(7,9) | 5 |
| KIMI | ||||
| 常见病 | 10(10,10) | 6(4,8) | 7(6,8) | 16 |
| 罕见病 | 10(10,10) | 6(4,8) | 8(6,9) | 6 |
| 危重症 | 10(10,10) | 8(6,8) | 8(8,9) | 4 |
| 合计 | 10(10,10) | 6(4,8) | 8(6,9) | 26 |
| ChatGPT 4.1 | ||||
| 常见病 | 10(9,10) | 6(4,7) | 7(5,8) | 18 |
| 罕见病 | 10(9,10) | 4(2,7) | 7(4,8) | 8 |
| 危重症 | 10(9,10) | 7(4,8) | 7(6,8) | 6 |
| 合计 | 10(9,10) | 6(3,7) | 7(5,8) | 32 |
| LLM | 异常指标识别/分 | 异常原因分析/分 | 临床建议/分 | “幻觉”病例数/分 |
|---|---|---|---|---|
| DeepSeek R1 | ||||
| 常见病 | 10(10,10) | 9(8,9) | 9(8,9) | 6 |
| 罕见病 | 10(10,10) | 9(9,9) | 9(8,9) | 0 |
| 危重症 | 10(10,10) | 9(8,9) | 8(8,9) | 0 |
| 合计 | 10(10,10) | 9(8,9) | 8(8,9) | 6 |
| Qwen 3 | ||||
| 常见病 | 10(10,10) | 8(6,8) | 8(7,9) | 5 |
| 罕见病 | 10(10,10) | 8(6,8) | 8(7,9) | 0 |
| 危重症 | 10(10,10) | 8(6,9) | 9(8,9) | 0 |
| 合计 | 10(10,10) | 8(6,8) | 8(7,9) | 5 |
| KIMI | ||||
| 常见病 | 10(10,10) | 6(4,8) | 7(6,8) | 16 |
| 罕见病 | 10(10,10) | 6(4,8) | 8(6,9) | 6 |
| 危重症 | 10(10,10) | 8(6,8) | 8(8,9) | 4 |
| 合计 | 10(10,10) | 6(4,8) | 8(6,9) | 26 |
| ChatGPT 4.1 | ||||
| 常见病 | 10(9,10) | 6(4,7) | 7(5,8) | 18 |
| 罕见病 | 10(9,10) | 4(2,7) | 7(4,8) | 8 |
| 危重症 | 10(9,10) | 7(4,8) | 7(6,8) | 6 |
| 合计 | 10(9,10) | 6(3,7) | 7(5,8) | 32 |
| LLM | 解读内容注 | 解读特点 | 评分 | ||
|---|---|---|---|---|---|
| 异常指标识别/分 | 异常原因分析/分 | 临床建议/分 | |||
| DeepSeek R1 | 无明确异常指标;结合临床背景,分析肝衰竭相关代谢紊乱、隐匿性肿瘤、病毒性肝炎、酒精性肝病等风险;评估肝功能分级,补充血氨等检验,定期复查相关指标 | 报告解读基本正确 | 10 (10,10) | 8 (8,9) | 8 (8,8) |
| Qwen 3 | 无异常指标;结合临床背景,考虑肝衰竭影响,铁蛋白接近正常上限,可能有肝细胞损伤或炎症反应;肝衰竭支持治疗,监测相关指标 | 报告解读基本正确 | 10 (9.75,10) | 7 (6,8) | 8 (7.5,9.25) |
| KIMI | 异常值识别糖类抗原125为升高;异常原因分析围绕糖类抗原125异常,提示肝功能异常、炎症反应、潜在肿瘤风险;临床建议评估肝病风险,补充CT检查和肿瘤指标,建议监测糖类抗原125 | 存在“幻觉”现象,错误识别糖类抗原125为异常值,原因分析误导 | 3.5 (1,6) | 4 (3.75,4.75) | 7.5 (6.25,8.25) |
| ChatGPT 4.1 | 异常值识别铁蛋白升高;异常原因分析围绕铁蛋白异常,包括慢性炎症或感染、铁负荷过重、恶性肿瘤;临床建议评估肝功能及潜在并发症,补充铁相关检测 | 存在“幻觉”现象,错误识别铁蛋白异常值,过度强调铁代谢评估 | 1 (1,3) | 4 (1.75,7) | 6.5 (4,8) |
| LLM | 解读内容注 | 解读特点 | 评分 | ||
|---|---|---|---|---|---|
| 异常指标识别/分 | 异常原因分析/分 | 临床建议/分 | |||
| DeepSeek R1 | 无明确异常指标;结合临床背景,分析肝衰竭相关代谢紊乱、隐匿性肿瘤、病毒性肝炎、酒精性肝病等风险;评估肝功能分级,补充血氨等检验,定期复查相关指标 | 报告解读基本正确 | 10 (10,10) | 8 (8,9) | 8 (8,8) |
| Qwen 3 | 无异常指标;结合临床背景,考虑肝衰竭影响,铁蛋白接近正常上限,可能有肝细胞损伤或炎症反应;肝衰竭支持治疗,监测相关指标 | 报告解读基本正确 | 10 (9.75,10) | 7 (6,8) | 8 (7.5,9.25) |
| KIMI | 异常值识别糖类抗原125为升高;异常原因分析围绕糖类抗原125异常,提示肝功能异常、炎症反应、潜在肿瘤风险;临床建议评估肝病风险,补充CT检查和肿瘤指标,建议监测糖类抗原125 | 存在“幻觉”现象,错误识别糖类抗原125为异常值,原因分析误导 | 3.5 (1,6) | 4 (3.75,4.75) | 7.5 (6.25,8.25) |
| ChatGPT 4.1 | 异常值识别铁蛋白升高;异常原因分析围绕铁蛋白异常,包括慢性炎症或感染、铁负荷过重、恶性肿瘤;临床建议评估肝功能及潜在并发症,补充铁相关检测 | 存在“幻觉”现象,错误识别铁蛋白异常值,过度强调铁代谢评估 | 1 (1,3) | 4 (1.75,7) | 6.5 (4,8) |
| [1] |
TORDJMAN M, LIU Z, YUCE M, et al. Comparative benchmarking of the DeepSeek large language model on medical tasks and clinical reasoning[J]. Nat Med, 2025, 31(8):2550-2555.
DOI |
| [2] |
MCCAFFREY P, JACKUPS R, SEHEULT J, et al. Evaluating use of generative artificial intelligence in clinical pathology practice:opportunities and the way forward[J]. Arch Pathol Lab Med, 2025, 149(2):130-141.
DOI URL |
| [3] |
GIRTON M R, GREENE D N, Messerlian G, et al. ChatGPT vs Medical Professional:analyzing responses to laboratory medicine questions on social media[J]. Clin Chem, 2024, 70(9):1122-1139.
DOI URL |
| [4] |
WANG A Y, LIN S, TRAN C, et al. Assessment of pathology domain-specific knowledge of ChatGPT and comparison to human performance[J]. Arch Pathol Lab Med, 2024, 148(10):1152-1158.
DOI PMID |
| [5] | HE Z, BHASURAN B, JIN Q, et al. Quality of answers of generative large language models versus peer users for interpreting laboratory test results for lay patients:evaluation study[J]. J Med Internet Res, 2024,26:e56655. |
| [6] | 陆小琴, 佳薇, 武宇翔, 等. 大语言模型在检验医学领域的应用潜力与挑战评估[J]. 临床检验杂志, 2024, 42(8):619-623. |
| [7] |
SANDMANN S, HEGSELMANN S, FUJARSKIM, et al. Benchmark evaluation of DeepSeek large language models in clinical decision-making[J]. Nat Med, 2025, 31(8):2546-2549.
DOI |
| [8] |
HAN W, WAN C, SHAN R, et al. Evaluation of error detection and treatment recommendations in nucleic acid test reports using ChatGPT models[J]. Clin Chem Lab Med, 2025, 63(9):1698-1708.
DOI URL |
| [9] |
CADAMURO J, CABITZA F, DEBELJAK Z, et al. Potentials and pitfalls of ChatGPT and natural-language artificial intelligence models for the understanding of laboratory medicine test results[J]. Clin Chem Lab Med, 2023, 61(7):1158-1166.
DOI URL |
| [10] | 中华人民共和国国家卫生健康委员会. 中国卫生健康统计年鉴[M]. 北京: 中国协和医科大学出版社, 2023. |
| [11] | 国家卫生健康委员会, 科学技术部, 工业和信息化部, 等. 国卫医发〔2018〕10号关于印发第一批罕见病目录的通知[EB/OL].(2018-05-11)[2025-05-23]. https://www.gov.cn/zhengce/zhengceku/2018-12/31/content_5435167.htm. |
| [12] | 国家卫生健康委员会, 科学技术部, 工业和信息化部, 等. 国卫医发〔2023〕26号关于印发第二批罕见病目录的通知[EB/OL].(2023-09-18)[2025-05-23]. https://www.gov.cn/zhengce/zhengceku/202309/content_6905273.htm. |
| [13] | 杨大干. 数智临床实验室[M]. 北京: 科学出版社, 2024. |
| [14] |
FARES M Y, PARMAR T, BOUFADELP, et al. An assessment of the performance of different chatbots on shoulder and elbow questions[J]. J Clin Med, 2025, 14(7):2289.
DOI URL |
| [15] | PILLAY T S, TOPCU D İ, YENICE S. Harnessing AI for enhanced evidence-based laboratory medicine(EBLM)[J]. Clin Chim Acta, 2025,569:120181. |
| [16] | CHEN J, MA J, YU J, et al. A comparative analysis of large language models on clinical questions for autoimmune diseases[J]. Front Digit Health, 2025,7:1530442. |
| [17] | YAN C, LI Z, LIANG Y, et al. Assessing large language models as assistive tools in medical consultations for Kawasaki disease[J]. Front Artif Intell, 2025,8:1571503. |
| [18] |
PLEBANI M. ChatGPT:angel or demond?Critical thinking is still needed[J]. Clin Chem Lab Med, 2023, 61(7):1131-1132.
DOI URL |
| [19] |
SINGH R, KIM J Y, GLASSY E F, et al. Introduction to generative artificial intelligence:contextualizing the future[J]. Arch Pathol Lab Med, 2025, 149(2):112-122.
DOI URL |
| [20] |
LOFTUS T J, HAIDER A, UPCHURCH G R Jr. Practical guide to artificial intelligence,chatbots,and large language models in conducting and reporting research[J]. JAMA Surg, 2025, 160(5):588-589.
DOI URL |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||